W internecie nic nie ginie (nawet Google+)
 Tomasz Torcz
Tomasz Torcz
Blog został ubogacony ponad pół tysiącem moich wpisów z Google+ z lat 2011÷2018. Są pod tagiem googleplus.
Wpisy niepubliczne zostały odtajnione.
Blog został ubogacony ponad pół tysiącem moich wpisów z Google+ z lat 2011÷2018. Są pod tagiem googleplus.
Wpisy niepubliczne zostały odtajnione.
Po kilku latach pracy zdalnej noszę się z zamiarem sprzedaży jednego z samochodów. Głównie stoi pod blokiem, więc co go ruszę to się psuje. Ale komunikacja miejska jest w Gdańsku fatalna, Traficar nie zawsze jest w okolicy, taksówek nie lubię, a czasem trzeba gdzieś dojechać.
Do tego pora też już na kryzys wieku średniego. Jeździć na Harley Davidsonie Żona mi nie pozwala. Więc może kupić sobie elektryka? Zbiegiem okoliczności, w zeszłym roku zacząłem poruszać się nieślubnym dzieckiem motoru i samochodu elektrycznego.
Udział w konferencji KubeCon NA 2022 zakończyłem z hulajnogą elektryczną (dzięki, CloudCasa!). Stuknęło mi właśnie 640 przejechanych kilometrów, więc pora na trochę refleksji. Spoiler alert – jest fun!
Gdańsk jak wiadomo jest miastem górzystym. Mieszkam na 90m n.p.m, jadąc np. na ściankę wspinaczkową muszę przekroczyć punkt o wysokości 111m. Rowerem jest to już dla mnie męczące. Hulajka daje radę, chociaż na niektórych podjazdach znacząco zwalnia. Będzie lepiej jak schudnę ;)
Zasięg po mieście nie stanowi problemu, ale też najdłuższą trasę jaką zrobiłem to do Schroniska Promyk i z powrotem. Około 30 km, przewyższenia 70 metrów. Nawet na imprezę w Sopocie wolałem pojechać jednośladem niż komunikacją miejską. W jedną stronę godzinka, trasę powrotną hulajnoga zrobiła w bagażniku taksówki.
Zaskoczyły mnie czasu przejazdów w porównaniu z samochodem. Na trasach miejskich, którymi jeżdżę, są… porównywalne. Na drogach dla rowerów jest dużo mniej sygnalizatorów świetlnych niż na drogach. Samochodem często stoję i czekam na zielone, w tym czasie po DDR można przejechać bez zatrzymania.
Raz miałem sytuację deszczu uniemożliwiającego szybszą jazdę. Jednak znalezienie w pobliżu samochodu z carsharing, zapakowanie pomykacza do bagażnika i powrót do domu zajęło mi więcej czasu, niż jakbym powoli jechał hulajnogą.
Cenowo ten minielektryczny pojazd jest nie do pobicia. Załadowanie do pełna w zeszłym roku kosztowało ok. 45 gr. Koszt przejechania kilometra poniżej 2 groszy!
I na koniec, co dla niektórych jest ważne: na hulajnodze wygląda się całkiem nieźle.
Krąży po necie taki obrazek osoby, której wydaje się zabawne, że odświeżacz powietrza może mieć nadany adres IPv4:
What a great idea!
— 𝔅͛𝔯͛𝔦͛𝔞͛𝔫͛ ͛𝔚͛𝔥͛𝔢͛𝔩͛𝔱͛𝔬͛𝔫͛ (@brianwhelton) April 24, 2022
I’m going to start putting Ip addresses on random things. pic.twitter.com/4aYGAHRFg1
Otóż kto poszedł w smart home, ten się w cyrku nie śmieje. No mojej liście widnieje:
7 d1mini04 - odświeżacz WC
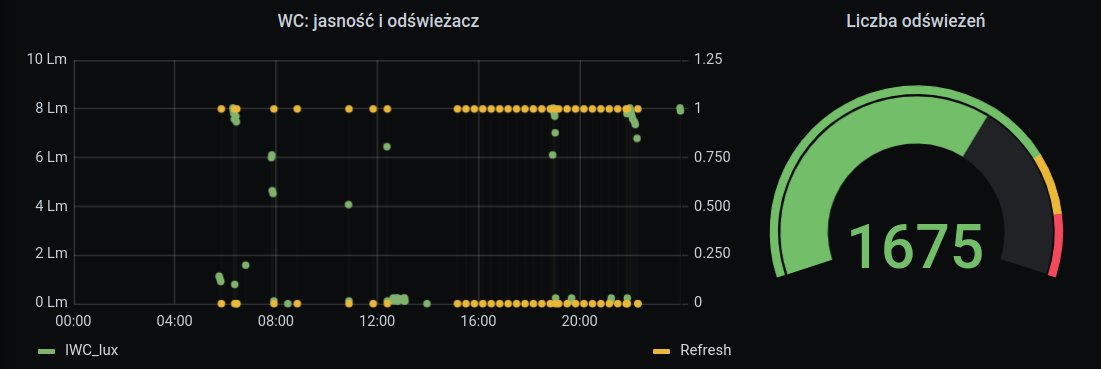
Taki odświeżacz to w bardzo proste urządzenie. Dwie baterie i przełącznik: 9–18–36 minut. Po włączeniu, co zadany czas dźwignia naciska na chwilę ujście puszki ze środkiem zapachowym. I tak przez 24h na dobę, niezależenie czy ma to sens czy nie.
A gdyby tak…

Tak rozbudowany odświeżacz:
ma czujnik światła; psiknięcie następuje gdy najpierw jest jasno, a potem zapada ciemność – ktoś był w WC, a potem je opuścił i zgasił światło
w nocy nie psika, bo na co to komu?
nie psika też jak jesteśmy na wyjeździe i dom jest ustawiony w tryb wakacyjny
a jak już odświeża, to w dowolnych interwałach, a nie trzech narzuconych przez producenta
liczy ile było psiknięć, co pozwala przygotować się do wymiany wkładu
Modyfikacja była bardzo prosta, bo pierwsze wciśnięcie dźwigni następuje zaraz po włączeniu urządzenia. Steruje więc tranzystorem podając napięcie na mechanizm. Następuje psiknięcie, tranzystor wyłączam. W OpenHAB wygląda to tak:
Switch sD1MINI04_refresh "Odświeżenie WC" <wifi> { mqtt=">[motherqtt:/d1mini04/gpio/14:command:ON:1],>[motherqtt:/d1mini04/gpio/14:command:OFF:0]", expire="6s,command=OFF" }
Kiedyś polutowałem okap, żeby do niego gadać. Odświeżacz jest na tyle smart, że wie jak i kiedy ma robić swoją robotę. Bez gadania.
Już blisko trzy lata odkąd postanowiłem przeczytać wszystkie książki z uniwersum Diuny. Koniec już widać – jeszcze tylko 5+1 książek i kilka opowiadań. Postanowiłem jednak zrobić przerwę i poczytać inne pozycje. Akurat jestem między „Dziećmi” a „Bogiem Imperatorem”, czyli w chronologii uniwersum następuje przeskok o tysiące lat. Co ciekawe, „Bóg Imperator” był pierwszą diunową książką którą kiedykolwiek przeczytałem, a było to w wakacje po 7. klasie podstawówki.
Projekt Gom Dżabbar planuję zakończyć w przyszłym roku. Wynik do przerwy:
Tytuł |
Wydanie |
Przeczytane |
|---|---|---|
"Hunting Harkonnens" |
2002 |
09.07.2019 |
The Butlerian Jihad |
2002 |
15.08.2019 |
"Whipping Mek" |
2003 |
22.08.2019 |
The Machine Crusade |
2003 |
29.11.2019 |
The Faces of a Martyr |
2004 |
01.12.2019 |
The Battle of Corrin |
2004 |
29.01.2020 |
Sisterhood of Dune |
2012 |
02.04.2020 |
Mentats of Dune |
2014 |
08.06.2020 |
"Red Plague" |
2016 |
08.06.2020 |
Navigators of Dune |
2016 |
19.07.2020 |
House Atreides |
1999 |
22.10.2020 |
House Harkonnen |
2000 |
10.01.2021 |
House Corrino |
2001 |
07.03.2021 |
Paul of Dune (Parts II, IV, VI) |
2008 |
24.07.2021 |
"Wedding Silk" |
2011 |
25.07.2021 |
The Winds of Dune (Part II) |
2009 |
04.08.2021 |
The Duke of Caladan |
2020 |
09.10.2021 |
The Lady of Caladan |
2021 |
15.05.2022 |
The Heir of Caladan |
2022 |
|
Dune |
1965 |
17.10.2021 |
"Whisper of Caladan Seas" |
2001 |
17.10.2021 |
"Blood of the Sardaukar" |
2019 |
22.10.2021 |
"The Waters of Kanly" |
2017 |
20.10.2021 |
Paul of Dune (Parts I, III, V, VII) |
2008 |
21.11.2021 |
The Winds of Dune (Part IV) |
2009 |
26.11.2021 |
"The Road to Dune" |
1985 |
19.12.2021 |
Dune Messiah |
1969 |
30.12.2021 |
The Winds of Dune (Parts I, III, V) |
2009 |
22.01.2022 |
Children of Dune |
1976 |
11.03.2022 |
God Emperor of Dune |
1981 |
|
Heretics of Dune |
1984 |
|
Chapterhouse: Dune |
1985 |
|
"Sea Child" |
2006 |
|
"Treasure in the Sand" |
2006 |
|
Hunters of Dune |
2006 |
|
Sandworms of Dune |
2007 |
W przerwie mam zamiar nadrobić książki niebeletrystyczne. Zebrało się tego trochę, patrząc to co mam napoczęte i czekające na Kindle i na półce: The Manager's Path, The DevOps Handbook, The Making of a Manager, Critical Chain, Turner Diaries, Think Again, Remote, Public Speaking Fastlane, Łowcy Szpiegów, Człowiek i błędy ewolucji, The Black Swan, Antifragile, Effective DevOps, Blackout, Zones of Thought, Software Architecture for Big Data and the Cloud.
A potem… mam przeczytane kilka tomów „Gry o tron”, The Expanse kusi, Trylogia Marsjańska autorstwa Kim Stanley Robinson też, może bobiverse, serię Culture wypadało by znać, twórczość Dukaja też. TODO długie, życie krótkie.
Having just spent hours debugging simple Flask application, I need to went:
1. tzdata package in fedora-minimal container image is broken.
RPM database lists files which are not installed (actually, they were removed during base container build). It's getting fixed.
Symptom: FileNotFoundError: [Errno 2] No such file or directory: '/usr/share/zoneinfo/zone.tab'
Workaround: microdnf reinstall tzdata.
2. HTML checkboxes are weird. When they are set, they appear in HTTP request data with value. When unset, they are not in the
request (i.e. one cannot look for checked = False). Thus, following is enough to find if the checkbox has been checked:
3. default-on checkboxes with state retained over POST… This one was tricky. Apparently, initialising Flask-WTForms with request data on the first load overwrites default state. Solution: use form data in POST handler only.
class SomeForm(FlaskForm): checkbox_name = BooleanField("Some label", default=True) @app.route("/", methods=["GET", "POST"]) def main(): # doing "form = SomeForm(request.form)" here would obliterate default checkbox state; don't do it if request.method == "POST": form = SomeForm(request.form) … else: # not a POST? start with default, empty form form = SomeForm() …
Software neglect forces perfectly good hardware obsolete. I was suprised it could strike such basic devices as an ethernet switch.
Few years ago I bought a TP-Link gigabit switch for home network. TL-SG2216 model ticked all the
boxes: 16 ports, 2 SFP slots (if I ever get FTTH), VLANs, IPv6 support and remote management, 5 years warranty.
Although ssh required strange dances since the beginning
(ssh -oKexAlgorithms=+diffie-hellman-group1-sha1 -oCiphers=aes256-cbc -oHostKeyAlgorithms=+ssh-dss …), the HTTPS
interface worked fine. Until it broke last year.
Firefox was adamant – SSL_ERROR_NO_CYPHER_OVERLAP. Chromium threw similar tantrum: ERR_SSL_VERSION_OR_CIPHER_MISMATCH. HTTPS management UI on my switch ceased to be secure enough for modern browsers. The world rushed forward, obsoleting and disabling old, unsecure algorthms and protocols. In the meantime my switch stood still. Eventually the world surpassed what was possible with TP-Link.
From my perspective, the web UI broke. I bought a switch with HTTPS management, and this feature stopped working. So, in the last days of my warranty coverage, I reported the issue to TP-Link. Long story short, it was denied on a technicality. I should have opened the issue through the distributor who sold me the switch, not directly with TP-Link. I've got this information after the warranty lapsed, which ended the story.
But frankly, I do not think TP-Link would be able to salvage this situation. I put only a tiny blame on them.
They designed the switch couple years ago. It was good enough and worked with the ecosystem of its time. They provided couple minor firmware upgrades, and after a decade on the market, EOLed the switch.
It is the world which changed.
Couple decades ago, network hardware once deployed would be working for years, practically forever. Security risks weren't so serious as we have now. No one would deprecate and remove protocols in the name of security. How long 3DES (hell, even single DES?) was with us?
Today, security is paramount. Our lifes are entwined with TCP/IP services. Protocols are phased out and improved when needed. Web browsers automatically update to newer versions. And this is good. But manufactures need to catch up. Product development cannot end when market availability starts. Fixes, updates are required to do more work to retain functionality. Even bigger changes like adding new TLS protocol needs to happen during the device lifetime. We need regulators (like EU) to enforce that.
We also need to vote with our wallets. Maybe pay a bit more, but buy from companies providing better support for their products, through their shelf-life and beyond. Couple of years ago I was dissapointed [2] with Motorola not delivering on promise of upgrades for Moto G. I will not buy Motorola Android phone again.
What options do I have with the switch?
I could replace the switch with something modern, but it's just spending money and generating electro-waste.
I could get a little VM with obsolete operating system and an old browser just to manage this switch. This is unsafe, makes me shudder and is too cumbersome to even consider.
Finally, I can manage the device using plain, unencrypted HTTP. Given it's accessible in my LAN only, this is the way to go. I will be sad inside, but that's the only loss.
sslscan output below shows the sad state of TP-SG2216 web management:
Testing SSL server distrans.pipebreaker.pl on port 443 using SNI name distrans.pipebreaker.pl SSL/TLS Protocols: SSLv2 disabled SSLv3 disabled TLSv1.0 enabled TLSv1.1 disabled TLSv1.2 disabled TLSv1.3 disabled Supported Server Cipher(s): Preferred TLSv1.0 128 bits RC4-SHA Accepted TLSv1.0 128 bits RC4-MD5 Accepted TLSv1.0 112 bits DES-CBC3-SHA Accepted TLSv1.0 56 bits TLS_RSA_WITH_DES_CBC_SHA
Najlepszą motywację do skończenia projektu jest publiczne przyznanie, że się coś robi. Wtedy pojawia się presja…
W tajemnicy przed Żoną przygotowuje mały wyświetlacz prezentujący najważniejsze o poranku informacje. W weekend popisałem kilka odwołań do różnych API i na tę chwilę mam zebrane dane do wyświetlania:
$ ./epaper.py Czas: 6:56 --- Thunderstorm (burze z piorunami) Wiatr 63 km/h 2°C, odczuwalna -5°C --- Do Pruszcza * obwodnicą 26 min miastem 28 min --- [++ ] PM2,5: 4.52% ; [++ ] PM10: 2.94% Wspaniałe powietrze! / Korzystaj z życia!
Rano prezentowane informacje są nieco inne, niż w trakcie dnia:
aktualny czas; rano dokładny, później z dokładnościa do kwadransa
pogoda – bieżąca, wieczorem: prognoza na dzień następny; dane biorę z OpenWeatherMap
czas dojazdu do pracy, dwiema alternatywnymi drogami. Googlowy Directions API bierze pod uwagę aktualne natężenie ruchu. I podobno pierwsze $200 każdego miesiąca jest darmowe. Po południu ta informacja nie jest potrzebna – może zamiast tego pokazywać czas dojazdu do najbliższego wydarzenia z kalendarza, z wpisaną lokalizacją?
jakość powietrza informacyjnie, akurat mieszkam niedaleko kilku czujników Airly
Kwestia prezentacji zajęła mi więcej badań, bo chciałbym utrzymać wszystko w Pythonie. Spodobał mi się pewien wyświetlacz, ale informacje w necie nie były spójne. Za to idealnym wyczuciem wykazał się producent wyświetlacza. W weekend pokazali, że działa z MicroPython:
Test micropython to drive LILYGO T5-4.7 inch E-paper pic.twitter.com/bEFJLQDe3B
— LILYGO (@lilygo9) January 15, 2022
Więc zakupiłem. Zanim dojdzie z Chin, wsparcie dla MicroPythona będzie już gotowe.
Chances are you are reading this post on a blog aggregator (“planet”) named We Make Fedora (lack of link deliberate). We Make Fedora was apparently organised by Daniel Pocock. He copied all the blog sources from Planet Fedora, but mixed-in some shady, anonymous sources. This way, “conspiracy theory”-like nameless posts build on credibility of real Fedora developer's blogs.
I do not want neither my name nor mine posts to appear alongside such content. Examples of recent posts:
borderline slanderous posts about Chris Lamb, former Debian leadership (on allegely Fedora-related site!) personal matters
insinuations about trafficking of underage girls by open source communities, on one occasion implicating Justin W. Flory from Fedora
comparison between Adolf Hitler's activities (!!!) and German Free Software Foundation of Europe
equaling Google's Youth Hacking 4 Freedom with nazi Concentration Camps
Holocaust is a very painful memory for European society. It should never be forgotten, the memory should be treated with seriousness in places like Yad Vashem Institue. It should never be used in an anonymous slanderous content.
Again, I do not want my name used to legitimise above content. I've asked Daniel to remove my blog from his aggregator three times:
on Tue, 24 Aug 2021 12:00:33 +0200, in a direct email
on Mon, 6 Sep 2021 09:17:35 +0200, in an email to Daniel and fedora-devel (apparently still in moderation queue)
on Mon, 6 Sep 2021 17:08:42 +0200, in a reply to Daniel
Despite above efforts, my posts still appear on We Make Fedora. I don't want to see my name on a site with such dubious content. I going to block access to my RSS/ATOM feeds for the aggregator. Unfortunately anyone can utilize public feeds to create any site he wants.
This post will be short. Recent FreeIPA versions contain ACME server implementation, which makes TLS certificate issuance a breeze.
FreeIPA is a solution giving you LDAP for user accounts, CA for issuing certificates and Kerberos for SSO, delivered with nice WebUI in an integrated package.
Automated Certificate Management Environment is a protocol designed to automate process of getting a TLS certificate. It was popularised by Let's Encrypt, BuyPass, Venafi and others.
When you have FreeIPA, you have your own Certificate Authority. It is most sensible to use it for securing your internal endpoints. Your clients should already trust this CA. Your internal network may not be reachable by external ACME providers. And you may want to hide your internal hostnames from appearing in global Certificate Transparency Databases.
Ready to start? Make sure package pki-acme is installed on you FreeIPA server. Next, enable ACME functionality:
$ ipa-acme-manage enable
The ipa-acme-manage command was successful
Done! Now configure the client – for my k8s I'm using awesome cert-manager. Start with definition of a ClusterIssuer with your FreeIPA URL (put you own email and server address, of course):
--- kind: ClusterIssuer apiVersion: cert-manager.io/v1 metadata: name: pipebreaker-freeipa spec: acme: email: tomek@pipebreaker.pl server: https://ipa-ca.pipebreaker.pl/acme/directory privateKeySecretRef: # Secret resource that will be used to store the account's private key. name: issuer-pbrk-account-key solvers: - http01: ingress: {}
Second (and last) step is to annotate each ingress which should get a TLS certificate automatically provided:
--- kind: Ingress apiVersion: networking.k8s.io/v1 metadata: annotations: cert-manager.io/cluster-issuer: pipebreaker-freeipa […]
And that's basically it. After few moments certificate should be issued:
When using cert-manager, make sure it's version 1.6.0 or later. There was a fix for ambiguity in spec which solved some interoperability problems with FreeIPA implementation. The fix may be backported for older cert-manager releases.
Dwa lata temu postanowiłem przeczytać † wszystkie książki z uniwersum Diuny. Kulminacją miało być skończenie tytułowej powieści z 1965 tuż przed najnowszą ekranizacją.
Książkowy Kwisatz Haderach pojawił się o pokolenie za wcześnie. Nawiązując do tego, jeszcze w trakcie czytania Diuny poszedłem do kina na Dune: Part One tydzień temu, w trakcie pobytu w Hiszpani‡. Miesiąc przed zaplanowanym terminem.
Krótko mówiąc film doskonale ilustruje książkę. Kilkukrotnie uśmiechała mi się mordka – przelot ornitopterów nad pustynią jest piękny, inne ujęcia też. Bawi słowiański przykuc Fremenów, ale większych zastrzeżeń nie mam. Denis Villeneuve jest bardzo wizualnym twórcą i dał pokaz swoich umiejętności. Aktorzy dobrani bardzo dobrze, chociaż Chalamet chyba zbyt dosłownie potraktował przebudzenie na Arrakis. Przez pierwsze sceny wyglądał jakby bardzo potrzebował kawy. Natomiast Bautista jako Rabban – ideał. Mam nadzieję na więcej go będzie w drugiej części. Ujęcia z filmu powinny stać się kanoniczną ilustracją uniwersum Diuny.
Jednakże! Mimo sfilmowania 60% procent książki, zabrakło herbertowskiego budowania świata. Nie zmieściła się doskonała scena kolacji – chociaż to potrafię zrozumieć, trudno wprowadzić w filmie kilka postaci, które chwilę potem okazują się jednorazowe. Jednak mało innych opisów i rozmów. Są za to w nadmiarze wizje Paula, które są niejasne i dużo nie wnoszą. Jessika, jak na Bene Gesserit, była zbyt rozemocjonowana ⹋ – np. jej zachowanie w czasie lotu z Paulem w burzy koriolisa jest skrajnie różne od książkowego.
Dlatego powtarzam: jako ilustracja, film jest epicki. Mam jednak obawy, jak odbiorą go osoby nie znające materiału źródłowego. Nie jestem w stanie postawić się w ich miejscu - dla mnie o kilka dekad za późno – ale wiedząc czego brakuje mam pewien niedosyt.
Do polskiej premiery filmu zostało 25 dni.
Przypisy:
Czytanie prequeli przyrównałem do pudełka zawierającego ból. Nie ma ono konkretnej nazwy, natomiast gom dżabbar to używana przy okazji igła z trucizną.
czyli oryginalna ścieżka dźwiękowa z napisami.
umiejętności Bene Gesserit, w Star Treku jest Spock i Wolkanie w ogólności, Rycerze Jedi też kontrolują emocje, w „literaturze przygodowej” kamienna twarz jest zaletą wybitnych Natywnych Amerykanów (kiedyś zwanych Indianami). Ciekawe, jaki skutek ma wychowanie młodzieży na takiej literaturze?
Some time ago I've replaced Google Analytics with Plausible. It works great, except for one tiny thing. The map of visitors was empty. Due to various layers of Network Adress Translations in k3s networking setup, the original client IP address information was not reaching analytics engine.
There are solutions – there is a PROXY Protocol exactly for that case. And Traefik, which handles ingress in k3s, supports PROXY. Only a bit of gymnastic was needed.
Legacy IPv4 traffic entry point to my bare-metal cluster has a form of a small in-the-cloud virtual machine. It routes incoming TCP/443 traffic over the VPN into the cluster. The VM itself is not a part of kubernetes setup – I cannot run any pods on it. I've decided to use Ansible to configure it.
The outcome lives in k8s-haproxy-external-lb and gives me following map:
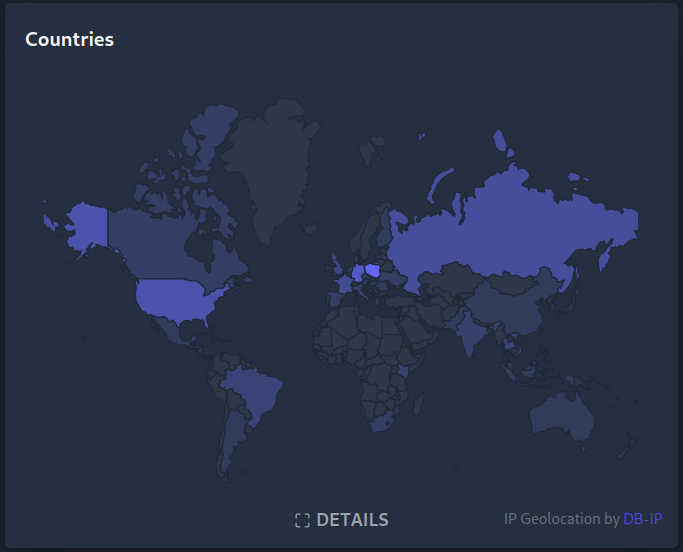
(greetings Australia, have you found information about the red LED on Sonoff?)
There are few moving parts, but with Python, Kubernetes and Ansible, the result is suprisingly simple:
there's a persistent pod running on the k8s cluster, watching EndPoints exposed by Traefik. When
a change occurs (traefik pod restart, replica count modification, etc.) – ansible playbook is triggered.
This pod may be seen as a k8s controller.
ansible playbook collects Traefik pod's IP addresses and ports.
JSON parsing in ansible is a bit suboptimal:
… | first | first | first looks bad but works.
still using ansible, haproxy configuration file is created, put on the edge nodes, and the service is restarted. I've selected haproxy because:
it implements PROXY protocol
haproxy passes received traffic directly to Traefik. This happens at the TCP level. TLS is terminated at Traefik, and certificates do not leave kubernetes cluster.
Some minimal preparations were needed. Communication between edge node and kubernetes pod network had to be established.
This was done in an instant, thanks to Wireguard.
SSH keypair for ansible had to be put in a k8s Secret and distributed among edge nodes. Finally, small fix
was needed in ansible itself: local connection plugin was not happy when run in a container, as random user without
an entry in /etc/passwd.
Traefik had to be configured to trust PROXY protocol information and generate X-Forwarded-For headers.
Plausible utilized information in those headers without additional tinkering.
Configuration details are described at https://github.com/zdzichu/k8s-haproxy-external-lb.
With the release of Linux kernel 5.12.11, bcache
is safe to use, again. The patch
bcache: avoid oversized read request in cache missing code path has been merged.
Due to changes in 5.12 kernels, bcache was prone to cause a BUG_ON() when submitting
large I/O requests. The result was a kernel panic or a system freeze. Problem was reported in
couple of places: Fedora bug#1965809,
bcache mailing list #1,
bcache mailing list #2.
When it comes to configurability, modern software often hits a sweet spot. We are given nice, usable User Interface (UI) helping with configuration – by hinting, auto-filling and validating fields. Additionaly, the configuration itself is stored in text format, making it easy to backup and track changes. For example in git version control system.
Recently I encountered at least two cases, where the above features conflict.
Argo CD is a wonderful tool to implement GitOps with you Kubernetes cluster.
Kubernetes is configured by plain text files in YAML format. That's a perfect form to track in git. Argo CD provides synchronization service: what you have in git repository is applied to kubernetes. Synchronization could be automatic or you can opt to sync manually. In later case, Argo CD provides a nice diff view, showing what's currently configured and how should it be.
Argo CD also has a nice concept of responsibility boundaries: it cares only about YAML sections and fields present in the git repo. If you add new section on the running cluster, it won't be touched. It may be a single field, for example – replicas:
Above can be utilized when you manage Argo CD by Argo CD. install.yaml file
defines configuration resources likes ConfigMaps and Secrets, yet
it doesn't provide actual data: sections. When you configure
Argo CD installation – using nice web UI, no less - data: sections
are created and configuration is stored into k8s cluster.
Those sections are not part of what is stored in git repository, so they will neither be touched nor rewritten.
But what happens when we want to store the Argo CD configuration in the repository, and gitops it to the Moon and back?
If we add data: sections, they will be synced. But we will lose ability
to use nice UI directly! As UI makes changes on the running cluster,
Argo CD will notice live configuration differs from git repository one.
It will overwrite our new configuration, undoing changes.
If we want to gitops configuration, we basically must stop using UI and manually add all changes to the text files in the repository!
Grafana is another cool project. It is a graphing/dashboarding/alerting solution, which looks pretty and is quite powerful, yet easy to use. Mainly because user interface is a pleasure to use; all changes are visible instantly and we are free to experiment.
Behind the scenes dashboards are just text (JSON) files. Great, text, let's store it in git! Well…
First of all, generated JSON tend to be dynamic. If you do some manipulations in the UI, sections in final file may move relative to each other. Even if the content does not change.
Second, those documents tend to be verbose. Like, really. It is not recommended to edit them manually, better use some templating language. For example grafonnet, which is a customisation of jsonnet - templating for JSON.
The reader probably sees where it's all going. Decision to use grafonnet makes the whole nice UI almost useless, as it spits JSON only. Again, to have better control, history and visibility we must forego one of the main selling points of the software.
Frankly, I don't see anything perfect. We have some workarounds, but they feel cumbersome.
For Argo CD we can disable self-healing of an app. That is, disable automatic synchronisation. That way we can still use the UI to do the configuration. Argo CD will notice out-of-sync status between git and live cluster. It will also provide helpful diff: showing exactly how changes made in the UI are reflected in the text configuration.
When we're happy with the changes, we have to extract them from diff view and commit to the git repository. Cumbersome. And we lose active counter-measurements against configuration drift.
Grafana problem we fight with sandbox instance. Any (templated) dashboard can be loaded, then customised with clickety click and exported to JSON. Now the tedious part begins: new stuff from JSON need to be identified, extracted, translated back into templating language and hand merged into grafonnet dashboard definition.
The improved dashboard should be imported into sandbox again and verified. If it is all right, it could be promoted to more important environments. Cumbersome².
I'm very interested in better solutions. If you have comments, ideas, links, please use comments section below!
Po dwóch dekadach prowadzeniach bloga można już polemizować z własnymi wpisami. Czasem nawet trzeba.
W czasie studiów na Wydziale ETI PG byłem pierwszym rocznikiem, na którym testowano nową formę zajęć – Projekt Grupowy. Odebrałem go źle i moje negatywne nastawienie utrzymało się długo. Dzisiaj – z bagażem doświadczeń – widzę w jak dużym błędzie byłem.
Z tego co pamiętam, Politechnika wprowadziła Projekt Grupowy (PG wprowadziła PG…) bo ktoś zorientował się, że brakuje przekazywania studentom umiejętności przydatnych w prawdziwym życiu/pracy:
pracy w grupie z podziałem obowiązków
tworzenia dokumentacji do rozwiązań
prezentowania, co się osiągnęło („sprzedania się”)
Dzisiaj zgadzam się, że powyższe są istotnymi zdolnościami. Samo ogarnięcie w technologii nie wystarcza. Wtedy byłem może nie idealistą, ale fascynatem technologii, bawiącym się ciekawymi rozwiązaniami i robiącym nowe rzeczy bo mogłem i bo były intrygujące.
Ciekawe jest, że zżymałem się na stwierdzenie „głównym zadaniem sieci telekomunikacyjnej jest przynoszenie zysku operatorowi ”. Well, duh! Dzisiaj potrzeba business case wydaje się jasna jak Słońce. Owszem, fajnie jest wymyślać nowe rzeczy, bo tak. Ale świat jest tak skonstruowany, że poza środowiskiem naukowym wszystko musi przynosić €€€. Nie ma sensu wydawanie milionów na sieć, aby popatrzeć jak ładnie pakiety się trasują. Rozwiązanie musi rozwiązywać czyjś problem i ta na tyle skutecznie, żeby takie ktosie były skłonne płacić za utrzymanie tego rozwiązania.
Do czego prowadzi oderwanie od biznesu mam niestety przykład w obecnej firmie. Po zainwestowaniu kilku lat pracy i stworzeniu systemu wg założeń dopiero zaczyna się szukanie komu i po co miałby być potrzebny. Brak jasno określonego „jaki jest nasz cel, klient” powoduje, że ludzie nie wiedzą po co robią, nie czują sensu i odchodzą. Jak nie wiadomo do czego dążymy, jakie są warunki dostarczenia bądź zakończenia projektu, to nie można odpowiedzieć ile jeszcze. A niepewność rozwala każde poczucie bezpieczeństwa.
No, ale to dygresja. Przy Projekcie Grupowym jeżyłem się też z powodu słownictwa w instrukcji. Niesłusznie. Może sformułowania nie były najzgrabniejsze, ale nie pozostawiały niedopowiedzeń. Było po prostu zostanie dostarczony, a nie jakieś powinien, musi, itp. Bo co, jeśli nie? Zamiast szukać odpowiedzi na przypadek nie, lepiej go w ogóle nie dopuścić. Teraz zgadzam się z takim podejściem.
Doświadczenie pokazało mi też jak powyższy problem wypływa w przypadku kiepskiego prawa. Mamy np. w ustawie o wspólnotach stwierdzenia, że Zarząd na wniosek zwołuje zebranie, albo że powinien uzyskać absolutorium. A co jeśli nie zwoła lub nie uzyska? Absolutnie nic. Brak penalizacji za niewywiązanie się powoduje, że takie zapisy są martwe, nie mają konsekwencji.
Moje studenckie oburzenie porównałbym do dramy, gdy do szkół niższego stopnia wprowadzono egzaminy opierające się na zrobieniu prezentacji. Że to niby spłycanie i uczenie kolorowania slajdów zamiast twardych konkretów. Tak się jednak składa, że prezentacja osiągnięć to cholernie ważna umiejętność i element całości.
Można sobie siedzieć w piwnicy i robić cuda, ale bez wyjścia z nimi do ludzi umrą razem z autorem. Warto zauważyć, że za początek Linuksa przyjmujemy nie chwilę napisania pierwszej linijki kodu. Obchodzimy za to dzień, w którym 30 lat temu Torvalds wysłał posta, do ludzi, że ma taki hobbistyczny projekt, który nigdy nie będzie tak duży i profesjonalny jak GNU.
Dzisiaj mało kontentu. Taki trochę rant, trochę moje zdziwienie objawami.
Wymieniłem ostatnio wyświetlacz w salonie na większy. Jedną z jego funkcji jest bycie cyfrową ramką na zdjęcia, a te w 4k wyglądają lepiej. Do tego czasem obejrzenie jakiś mediów video albo casualowe granie (Stadia FTW).
Zaskakująco, nie zadziało od razu. Dotychczas wystarczało mi iGPU wbudowane w procesor, jednak możliwości tego w i7-3770 kończą się na 2560×1600 przez DisplayPort. Przez HDMI nawet mniej – 1920×1200. Trzeba wymienić sprzęt. Wstępnie postanowiłem poczekać na nowe APU od AMD, w międzyczasie zacząłem szukać jakieś taniej karty graficznej. Z uwagi na sterowniki jedynym sensownym wyjściem są Radeony.
Kolega pożyczył mi swojego Radeona VTX HD 7850. Parę lat temu topowa karta. Dzięki niej po raz pierwszy zobaczyłem 3840×2160 na nowym wyświetlaczu. Ale! Nie było możliwości uzyskania więcej niż 30Hz. Wyjście HDMI było w zbyt starej wersji. Kartę więc oddałem i zacząłem szukać czegoś nowszego.
Wytypowałem i kupiłem na OLX kartę z serii RX 560. Obraz super, odświeżanie 60Hz bez problemu. Natomiast dźwięk przez HDMI – już nie bardzo. Wydawało mi się, że na początku działał, potem cisza. Może oszczędzanie energii zawiniło? Próbowałem z opcjami wysyłania cichego szumu i utrzymania urządzenia w akrtywności, ale bez sukcesów.
W wyniku pogłębionego researchu dodałem do linii poleceń jądra amdgpu.dc=1 amdgpu.audio=1 co z początku
zadziałało, ale nie na długo. Dodam, że eksperymenty są dość uciążliwe, bo komputer o którym
mowa służy mi też za router do internetu i centrum smart home. Problemu nie rozwiązałem, na szybko
przeciągnąłem kable i podpiąłem stare głośniki do komputera.
Jakiś czas później postanowiłem przejrzeć ustawienia samego wyświetlacza. W menu znalazłem pozycję „Rozszerzenie sygnału wejściowego” (po angielsku to chyba “Input Signal Plus”). Jej włączenie spowodowało, że wyświetlacz zaczął raportować obsługę trybów do 120Hz. Hmm. Aż tyle nie udało mi się włączyć, ale wyszedłem trochę ponad 60Hz. Obraz był, natomiast pojawiły się artefakty. Coś jakby kabel był uszkodzony, albo nie dawał rady.
Kabel! Niby pierdoła, ale obecny mam od prawie dziesięciu lat. Kiedy standardy HDMI były mniej wyżyłowane, a 4k to była egzotyka. Tak się złożyło, że miałem inny, nowszy 5-metrowy (komputer stoi w innym pomieszczeniu) przewód HDMI pod ręką. Zamieniłem. Obraz stabilny. I dźwięk też po prostu działa. Hmm!
Wyszło na to, że źródłem problemu jest zbyt stary kabel HDMI, nie zapewniający odpowiedniego pasma przenoszenia. Faktycznie dźwięk po nim działał w rozdzielczości FullHD. Po przełączeniu na 4k, dostępnego pasma już nie starczało na przesłanie audio. Przełączniki do kernela pewnie nie były potrzebne. Nowszy kabel pozwolił na 4k@60Hz z audio, ale osiągnięcie 120Hz też go przerosło.
Wyjaśniło się też, czemu czasami dźwięk był. Przy rozdzielczości Full HD, domyślnej po reboocie, starczało pasma na dźwięk. Przestawienie na 4k już pasmo wyczerpywało i dźwięk magicznie cichł.
Upgrade serwera zostawiam na później – teraz działa, nie mam motywacji do składania nowego. Co prawda jest trochę gorzej – mało slotów PCIe, po włożeniu karty graficznej NVMe musiał powędrować do gniazda 1x – ale nie jest to odczuwalne. A z kablami HDMI zrobiliśmy podobny burdel jak z USB-C. Kabel kablowi nierówny, trzeba dokładnie czytać co obsługuje. Do tego ze znalezieniem HDMI 5-metrowego future-proof (8K z HDR) jest problem.
Jak pisałem około roku temu, w związku z nową ekranizacją Diuny postanowiłem przeczytać wszystkie książki z uniwersum. Niektóre po raz kolejny, większość jednak po raz pierwszy. O Shai Huludzie, ale trafny kryptonim wybrałem! Jestem mniej więcej w połowie. Premiera filmu została przesunięta, więc tempo czytania mi spadło. A pan Herbert Junior w dalszym ciągu dopycha linię czasu (The Duke of Caladan wyszło w październiku).
Dotychczasowy mój postęp wygląda tak:
Tytuł |
Wydanie |
Przeczytane |
|---|---|---|
"Hunting Harkonnens" |
2002 |
09.07.2019 |
The Butlerian Jihad |
2002 |
15.08.2019 |
"Whipping Mek" |
2003 |
22.08.2019 |
The Machine Crusade |
2003 |
29.11.2019 |
The Faces of a Martyr |
2004 |
01.12.2019 |
The Battle of Corrin |
2004 |
29.01.2020 |
Sisterhood of Dune |
2012 |
02.04.2020 |
Mentats of Dune |
2014 |
08.06.2020 |
"Red Plague" |
2016 |
08.06.2020 |
Navigators of Dune |
2016 |
19.07.2020 |
House Atreides |
1999 |
22.10.2020 |
House Harkonnen |
2000 |
10.01.2021 |
House Corrino |
2001 |
in progress |
Na początku chciałem jeszcze na bieżąco oceniać, ale po recenzji The Butlerian Jihad i recenzji The Battle of Corrin odpuściłem. Im dalej w las, tym więcej wydm. Jakość tych powieści nie zachęca do dodatkowego poświęcania swojego czasu. Z planu przeczytania wszystkich się nie wycofuję, bo zazwyczaj doprowadzam przedsięwzięcia do końca.
Z filmu mamy na razie trailer:
Jedno muszę przyznać: Dave Bautista jest idealny jako Glossu Rabban Harkonnen. Ilekroć pojawia się w książkach (a jest go sporo w prequelach) to widzę właśnie takiego, jak zagrał go Dave.
Do premieru filmu zostało 8 miesięcy i 9 dni.
Pandemic situation forced most of the conferences to go on-line. On the one hand, it's not the same experience as in-person attendance. On the other hand - I can participate in events I wouldn't be able to travel to. Therefore I took part in KubeCon + CloudNativeCon North America 2020 last November. Moving to online format reduced price from $1000+ to just $75, which made it easier to justify 😊. It was a bit unusual to be at work in the morning, then move to couch and stay at the conference past midnight.
The online setup was quite good. There were virtual "booths" one would expect at expo – with demos, links to more materials and exhibitor's crew available for chat. There were additional number of channels on CNCF Slack. I followed the announcement one, sponsors one (heaps of interesting information there!) and some run by specific companies.
During the Conference there were some "meet the maintainer" events and accompanying gatherings. Those mainly had a form of Zoom (the owners of Keybase) video meetings where one could chat with the developers. I liked these!
The main course of conference are talks. There were plenty. Sometimes there were a dozen or so parallel tracks, so I did not have a chance to watch everything. I'm slowly working through backlog of things I missed. The talks itself were pre-recorded, but after the talk there was a live Q&A session with the speaker. Sadly, the Q&A is not available in recordings below. I guess this was one of the exclusive perks for attendees.
Below you'll find part 1 of my selection of most interesting talks. Second part will be coming later, but you can find all descriptions and links to the videos at https://kccncna20.sched.com/.
PKI the Wrong Way: Simple TLS Mistakes and Surprising Consequences - Tabitha Sable, Datadog
The Quest for the Ultimate Kubernetes Homelab - Dan Garfield, Codefresh
Stop Writing Operators - Joe Thompson, HashiCorp
Clean Up Your Room! What Does It Mean to Delete Something in K8s - Aaron Alpar, Kasten
How to Multiply the Power of Argo Projects By Using Them Together - Hong Wang
Stress and Mental Health in Technology - Dr. Jennifer Akullian, Growth Coaching Institute
The Open Source Revolution: How Kubernetes is Changing the Games Industry - Dominic Green
Admission Control, We Have a Problem - Ryan Jarvinen, Red Hat
High Performance KubeVirt in Action - Huamin Chen, Red Hat & Marcin Franczyk, Kubermatic
This one is from last year, but interesting: How the Department of Defense Moved to Kubernetes and Istio - Nicolas Chaillan
An observation: as for virtual conference, this one had a hefty carbon footprint! Imagine how many planes were flown to deliver these:

After KubeCon I've decided to give k3s a try. And I'm impressed!
K3s is a small distribution of Kubernetes (k8s), Linux container orchestrator system. It's really tiny while being functional. One starts with a single 52MiB binary and after few seconds there's a functional installation with half a dozen of system pods. It's a far cry from OKD and its resource hunger. Of course, compared to OKD, there's much less functionality in k3s, but enough for most cases (including mine).
First, I'm writing now, because only recently cgroupsv2 support was added to k3s. Previously it just didn't work on modern systems, like Fedora.
Second, the etcd database, widely perceived as a mandatory part of k8s, is optional in k3s! By default
embedded SQLite is used – enough for simple scenarios. I'm particularly happy for Postgresql support. Yes,
you can have your Kubernetes working with pgsql.
But K3s is not a single-node solution only. Adding worker nodes is simple; High-Availability solutions for control-plane looks sound (haven't tried yet, but it's on my TODO).
For networking one can easily encrypt inter-node traffic using WireGuard. It's a matter of single switch for
provided flannel network backend. Higher level needs? k3s ships with Traefik (which supports ACME for getting
TLS certificates) and klipper-lb.
Unfortunately at the lowest level, networking still depends on iptables. This was horrible choice in the
beginning of Kubernetes, already 15 years obsolete when it was selected. With known performance problems:
nf-hipac tried to solve the problems when, in 2002? Huawei replaced iptables with Linux IP Virtual Server in 2017
to have k8s scale. But the solution is still not default in upstream Kubernetes.
Anyway, for small cluster k3s with iptables should work fine, but it has a potential to demolish your carefully tuned firewall configuration. So beware. For the positive aspect, go and read klipper-lb entire source code. This is world championship in simplicity and getting things done with existing infrastructure.
Keeping cluster up-to-date can be automated with system-upgrade-controller, which downloads new version
and restarts the services. Simple.
k3s is provided by our Rancher friends at SUSE. I strongly recommend giving it some attention
(at the moment INSTALL_K3S_COMMIT=fadc5a8057c244df11757cd47cc50cc4a4cf5887 works for me).
Besides, I vaguely remember one needs k8s cluster to build some Fedora content. ;)
Smarthome uskuteczniam oprogramowaniem openHAB. W wersji 1.8.x, bo w 2.0 zmienił się format konfiguracji, a nie chciało mi się jeszcze robić migracji. Linia 1.8 ostatnie wydanie miała w 2016 roku.
Jako system operacyjny na domowym serwerze używam Fedory. Dzisiaj zrobiłem aktualizację do wersji 33. W tej wersji w końcu systemową Javę podbito do wersji 11.
Mój openHAB na to:
Launching the openHAB runtime... WARNING: An illegal reflective access operation has occurred WARNING: Illegal reflective access by org.eclipse.osgi.internal.baseadaptor.BaseStorage (file:/opt/openhab-1.8.3/server/plugins/org.eclipse.osgi_3.8.2.v20130124-1349> WARNING: Please consider reporting this to the maintainers of org.eclipse.osgi.internal.baseadaptor.BaseStorage WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations WARNING: All illegal access operations will be denied in a future release
Czyli nie wstanę, tak będę leżał. Światła nie zgaszę, okapu nie wyłączę, odświeżacz powietrza w WC zasnął. Internety oczywiście wskazały na niekompatybilność z Java11.
Na całe szczęście w Fedorze jest jeszcze dostępna Java8, którą można podłożyć openhabowi. I znowu działa, mam kolejne parę miesięcy na migrację do nowszej wersji (3.0 za płotem). Ale dług technologiczny nawet w domu czeka, żeby znienacka ugryźć człowieka w tyłek.
Zbyt rzadko sobie przypominam, jakim jestem szczęściarzem, że wciągnąłem się w ekosystem Linuksowy. Tu wszystko jest możliwe. Nota bene zapoznałem się z Linuksem przypadkiem – kolega, który miał mi przegrać FreeBSD miał problem z… zamountowaniem dyskietki (było to w okolicach roku 1998). Przez brak FreeBSD skierowałem się po next best thing czyli lajnuksa.
Zmieniając trochę temat, mam różne mniej lub bardziej poważne hobby. Za to czasem spotyka mnie czułość od Żony. Np. przyszła mnie przytulić, gdy kolejna osoba zginęła chodząc po Himalajach (hobby niebezpieczne, nie moje), a ja akurat siedziałem w gabinecie z lutownicą (hobby bezpieczne, moje).
Ostatnio zgłębiam zasoby Youtube pod kątem współczesnych komputerów PC, konkretnie ich chłodzenia. Mój serwerek/media center to nie jest maszyna jakoś specjalnie wymagająca, nawet dedykowanej karty graficznej nie ma (gram na Stadii). Ma być cichy i trwały. Obejrzawszy jutuby zrobiłem więc porządek z kablami, poprawiłem obieg powietrza, dołożyłem wiatraczek, dwa, ewentualnie dziesięć.
Generalnie działa, czasami coś zmienię albo przełożę.
Prawdziwa zabawa to sterowanie. Podstawowym parametrem do regulacji jest prędkość obrotów wentylatorków. Przeszedłem już przez kilka opcji: sterowanie przez płytę główną, związanie prędkości z temperaturą dysków/NVMe, czy też uzależnienie od temperatury procesora (coretemp). Dorobiłem się po drodze przyjemnych wykresów. Nawet przypomniałem sobie trochę Teorii Sterowania ze studiów. Ostatnio doszedłem do wniosku, że dobrze by było reagować na podstawie temperatury cieczy chłodzącej, bo duża pojemność cieplna wody dobrze uśrednia przebiegi… ale nie mam zestawu mierzącego ten parametr.
Za to mam od paru lat czujniki temperatury typu 1wire. Wziąłem jeden z nich i przykleiłem do radiatora. Do tego napisałem paręnaście linijek w Pythonie. Osiągnąłem efekt wow.
% systemctl show -p StatusText fancontrol-onewire StatusText=Ambient: 26.1°C, water: 31.7°C, CPU: 39.0°C → PWM: 64
Na innych platformach byłbym zapewne ograniczony do własnościowego oprogramowania. Może byłoby w stanie odczytać temperaturę procesora, może czujniki na płycie głównej i w modułach RAM, ale na pewno nie jakieś zupełnie z kosmosu rzeczy na 1wire.
Jakby dobrze poszło, to we własnościowym sofcie może mógłbym wyrysować z grubsza krzywe zależności między temperaturą a prędkością wiatraczków. A mi się uwidziło zrobić zależność po sinusoidzie – z początku przyrost prędkości większy, potem mniejszy. W pythonie: ależ proszę bardzo. Co więcej, w obliczeniach biorę pod uwagę temperaturę powietrza wokół serwera. Z obserwacji mi wyszło, że w typowej sytuacji radiator jest cieplejszy od otoczenia o ok. 4,5°C. Jak to wyrazić w GUI? Praktycznie nie da rady.
Linux daje mi (mi, specjaliście IT; nie każdemu) mnóstwo swobody. Praktycznie co wymyślę mogę osiągnąć kilkoma prostymi integracjami. Jestem, kurcze, szczęściarzem, że trafiłem na tę platformę.