Pięć dlaczego przed elektroprzejażdżką
 Tomasz Torcz
Tomasz Torcz
Jako, że wolę jeździć z celem, oraz lubię dużą infrastrukturę*, to wymyśliłem objechanie większych stacji elektroenergetycznych w okolicy (niektóre są w środku malowniczych lasów). Przejazd bez zapisu na Stravie się nie liczy, Strava bez zdjęć jest nudna, a infrastruktury krytycznej nie można fotografować.
Nie można?

O zakazie wszyscy słyszeli, ale skąd się bierze? Czego dokładnie zakazuje? Innymi słowy, jaka jest podstawa prawna.
Przeszukując informacje prasowe można w końcu trafić na wzmiankę o Ustawie o obronie Ojczyzny z 2022. W niej znajduje się artykuł 616a,
o zakazie fotografowania obiektów szczególnie ważnych dla bezpieczeństwa lub obronności państwa. Zaczyna się od:
Zakazuje się, bez zezwolenia, fotografowania….
OK, moment. To można mieć zezwolenie?
W tym samym artykule jest opisane (pkt 10.) co musi zawierać wniosek o zgodę i jak wygląda zezwolenie (pkt 11.). Wniosek kieruje się do zarządcy obiektu.
Przy okazji: na obiektach, których dotyczy zakaz, musi być tablica „znak zakazu fotografowania”. Ale zanim pojadę nie miejsce to nie wiem, czy taka tablica tam jest czy nie. A czy dany obiekt w ogóle należy do infrastruktury krytycznej wynika z niejawnego rozporządzenia.
Kto jest zarządcą? Trochę czasu z OpenStreetMap, trochę przeglądania archiwalnych informacji prasowych i podzieliłem interesujące mnie obiekty na dwie grupy. Pierwszą (tymi większymi) zarządzają Polskie Sieci Energetyczne. Drugą grupą Energa Operator, spółka Orlenu działająca w północnej i środkowej Polsce.
PSE ma swój adres e-Doręczeń (i ePUAP) elegancko podane na stronie kontaktu. EOP nie za bardzo,
ale jak wysłałem prośbę o ich podanie na emaila centrala@, to tego samego dnia dostałem odpowiedź. We wniosku napisałem, że zdjęcia z
rowerem chcę wrzucić na media społecznościowe jako potwierdzenie przejechania trasy.
Punkt 6. wspomnianej wcześniej ustawy określa, jak wniosek ma być podpisany elektronicznie. Ja użyłem swojego Profilu Zaufanego. Z kolei punkt 7. daje zarządcom maksymalnie tydzień na odpowiedź.
Obydwie firmy zgodziły się, dając analogiczne wytyczne o powstrzymaniu się od fotografowania szczegółów zabezpieczeń.

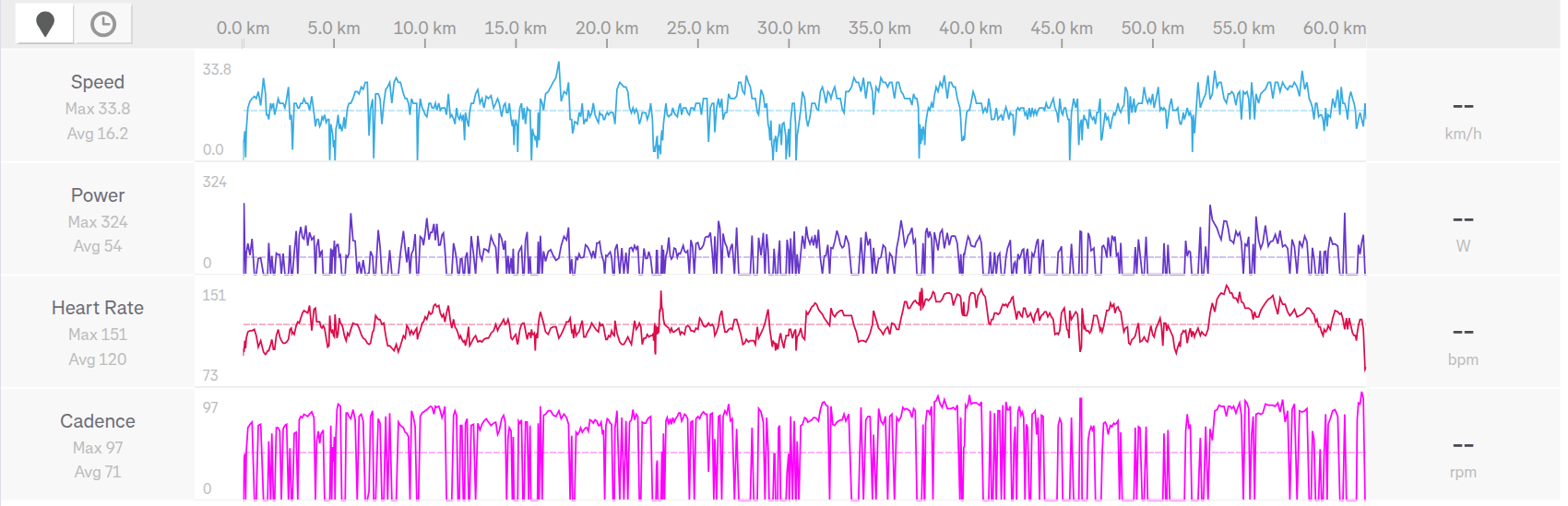
Trasa zamknęła się w 60 kilometrach. Przerwę na kawę i ciasto zrobiłem sobie we wiacie piknikowej koło świetlicy wiejskiej w Przyjaźni.
-
z nietypowych rzeczy, które zwiedzałem do tej pory: elektrociepłownia, wysypisko śmieci, spalarnia tychże (dwie sztuki), fabryka betonu i prefabrykatów, oczyszczalnia ścieków, dwa browary (trzeci może niedługo), polski reaktor atomowy Maria z przyległościami, stocznie w Gdańsku, port w Gdyni, centrum obsługi rowerów miejskich Mevo, kilka zbiorników/wież wodnych.
069/100 of #100DaysToOffload